Classifying data and applying proper handling is an important but somewhat complex task. On one hand, we have governance, which might be vague at best; on the other hand, we have operational teams trying to implement comprehensive handling mechanisms. In the middle, we have compliance reporting carried out by various teams trying to put everything together.
Governance
Data Classification and Handling start with proper governance that is enforced through clear and concise policies and standards.
What does that mean in the real world? It means the organization actually understands its data — what it owns, where it lives, and what level of protection it deserves.
A strong policy should outline the data classification categories and describe the potential impact of exposure, define what data fits into each classification, assign roles and accountability, and assigns enforceable and actionable standards.
Governance is not just about documents — it’s about ownership and accountability. Every piece of data should have an identified data owner who approves its classification, data stewards who make sure those rules are followed in daily operations, and data custodians who implement the technical controls to protect it.
Finally, governance only works when stakeholders — business, IT, and legal/compliance — stay aligned. Classification decisions can’t live in silos; they must be reviewed and agreed upon across all groups to ensure consistency and compliance across the organization
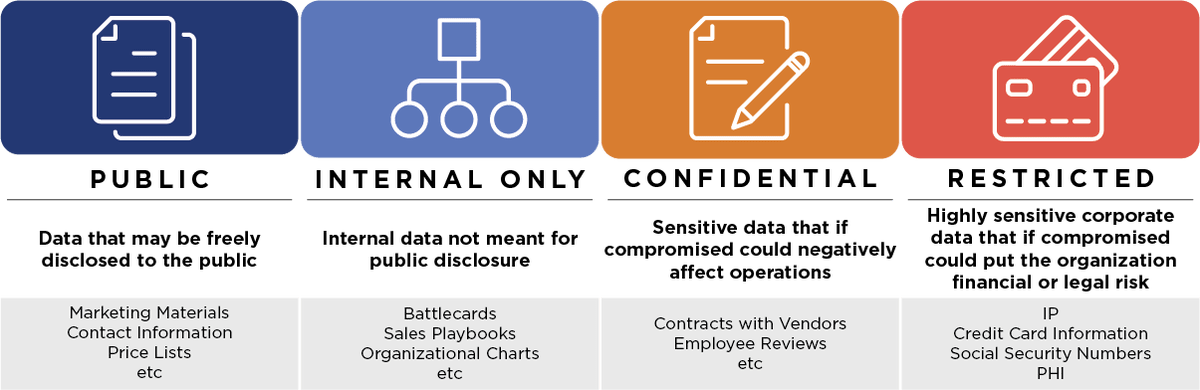
Data Classification
Data classification ensures that specific attributes are assigned proper category that correlates with the amount of risk it might present. While the common approach (listed below) is the industry standard, organizations might have their own classification framework. Adding more categories results in complexities that span people, process and technology, while keeping lower number of classifications might result in inconsistent approach to data handling.
1. Restricted
Meaning:
Restricted data represents the highest level of sensitivity. Unauthorized disclosure, alteration, or destruction of this information could cause severe harm to the organization.
Why / What belongs here:
This includes data protected by law, regulation, or contract — such as personal identifiers, financial records, or health information. Handling requires encryption, strict access controls, and continuous monitoring.
Example Data Attributes:
- Full name + government ID number (e.g., SSN, passport)
- Credit card or banking details
- Health or medical information (PHI)
- Authentication credentials (passwords, encryption keys)
- Legal or regulatory investigation documents
2. Confidential
Meaning:
Confidential data is sensitive information that, if exposed, could negatively impact the organization’s competitiveness, reputation, or compliance standing. It is protected by internal policy but not necessarily regulated by law.
Why / What belongs here:
Examples include proprietary business information, internal financials, or non-public project details. Access is limited to specific roles or departments, and sharing requires management authorization.
Example Data Attributes:
- Strategic business plans
- Non-public financial reports
- Customer contracts or proposals
- Source code or system configurations
- Employee performance data
3. Internal (or “Internal Use Only”)
Meaning:
Internal data is information intended for use within the organization. Disclosure outside the company would have minimal impact but could still reduce efficiency, trust, or competitive advantage.
Why / What belongs here:
Used for normal operations, such as internal communications, team documentation, or operational procedures. Access is limited to employees and trusted contractors.
Example Data Attributes:
- Internal memos and procedures
- Project timelines or meeting notes
- Internal training materials
- Employee directories (non-sensitive)
- Process documentation
4. Public
Meaning:
Public data is approved for release outside the organization. Its disclosure poses no risk to business operations, reputation, or compliance.
Why / What belongs here:
This includes marketing materials, published reports, or content explicitly designated for public consumption. No confidentiality controls are required, though accuracy and integrity remain important.
Example Data Attributes:
- Press releases and marketing brochures
- Publicly available policies
- Product or service descriptions
- Job postings
- Company website content
Obfuscation / Protection Techniques
Obfuscation is the action of making something obscure, unclear, or unintelligible.
- Encryption
- Used when data must remain confidential but still needs to be recoverable later
- Uses an algorithm + key to transform plaintext into ciphertext
- Reversible with the correct decryption key
- Masking
- Used for reducing exposure in UI, testing, or reports
- Obscures part of sensitive data for display while keeping its format recognizable (12324 for an account number).
- Replaces portions of the data with symbols while keeping structure recognizable
- Partially reversible (the original value is not recoverable from masked data)
- Tokenization
- Used in payment processing or identity management –where sensitive data must be referenced.
- Replace sensitive data with a non-sensitive equivalent (token)
- Maps original data to a random token stored in a secure lookup table (vault)
- Reversible only via the tokenization system — not by mathematical reversal
- Hashing (+salting/pepper)
- Used to verify integrity or authenticity — not to hide or recover data
- Uses one-way mathematical function that converts input into a fixed-length output (hash)
- Irreversible since there is no key that can restore the original
Data “states”
Data exists in three main states — in transit, at rest, and in use — and each requires a different set of security controls. Controls should be hardened and scale according to each classification.
In transit
This refers to data moving across networks, applications, or APIs. It should always be protected using secure protocols (TLS, VPN, etc.), use valid certificates and use application-level signing to prevent interception or tampering during transmission.
At rest
This is data stored on a physical or virtual medium. Encrypting data at rest can create a false sense of security if misunderstood.
- Disk-level encryption is primarily a physical control that protects against disk theft or improper disposal but offers little protection against malicious access
- File-level encryption is more granular and must always be paired with strong access controls
- Database-level encryption provides structured protection but must be supported by key and access management. Should be ‘hybrid’ in nature– protecting database files, access to schemas, individual tables and access to specific fields within a table.
- In-file encryption is encrypting specific values inside files — for example, hiding SSNs within a CSV. It’s difficult to manage at scale and introduces complications around key management, searching, or sharing files securely, but it’s still widely used when needed.
In use
As I haven’t been exposed to this type of data and have very little to say, I will only mention that this is data is actively processed in memory or by applications. Traditional encryption doesn’t apply once data is decrypted for use. Protection at this stage often relies on application-level controls, memory isolation, and runtime monitoring. Based on what I’ve seen, organizations still struggle to address such controls effectively, consistently and often accept residual risk.
The key is understanding that each data state demands its own controls, and their implementation should directly correspond to the data’s classification level — not all data deserves the same treatment, but all should have intentional protection.
Controls
An example matrix of basic controls that should be applied to each classification type and corresponding data state:
| Classification | At Rest | In Transit |
|---|---|---|
| Public | Standard storage, minimal restrictions, integrity maintained but no encryption required | Standard HTTPS or equivalent, no special encryption required |
| Internal | Controlled access, basic file permissions, regular backups | Encrypted channels (TLS 1.2+), internal VPN for sensitive systems |
| Confidential | File/database encryption, access control lists, audit logging, key management | TLS 1.3 or VPN, authentication required, integrity verification |
| Restricted | Strong encryption (AES-256), strict key management, access segmentation, continuous monitoring, DLP enforcement | End-to-end encryption(TLS 1.3 with mTLS or private tunnels), mutual authentication, private network or tunnel, session monitoring and alerting |
Data Lifecycle
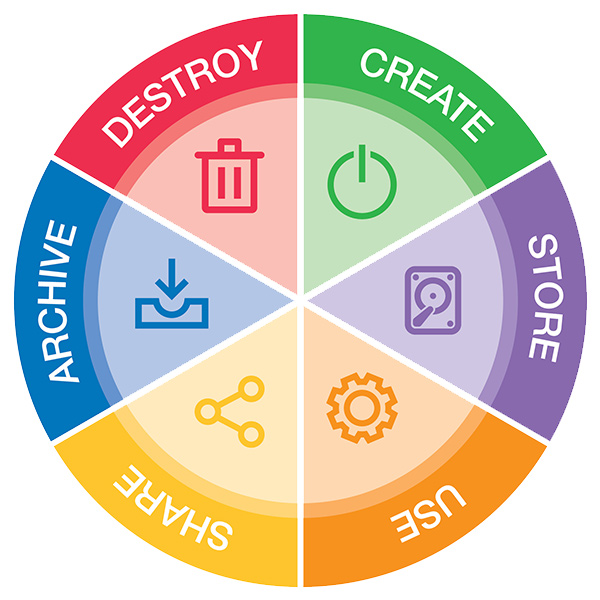
Data goes through a lifecycle. I used this variation that captures the high-level lifecycle. The lifecycle can be expanded, nonetheless, the basics don’t change:
- Create
This is the point where data first comes into existence — whether it’s entered manually, collected from a system, or generated by a process or device. It’s important that data is classified and labeled properly at creation to ensure it’s protected and handled correctly from the start - Store
Once created, data must be stored securely. This stage focuses on where and how data is kept — such as databases, file systems, or cloud storage — with proper access controls, encryption, and backups to protect against loss or unauthorized access. - Use
In this phase, data serves its intended purpose — being viewed, processed, analyzed, or modified. Proper handling, logging, and access management will ensure that use is compliant with policies. - Share
This stage requires careful consideration of who receives it, how it’s transmitted, and whether sharing aligns with policies. Secure transfer methods and data minimization are key practices here. - Archive
When data is no longer in active use but must be retained for legal, regulatory, or business reasons, it enters the archival stage. Archived data should be stored in a secure, retrievable format with defined retention periods and restricted access. - Destroy
At the end of its retention period, data should be permanently destroyed or deleted in a way that prevents recovery. This includes securely wiping electronic files and physically shredding paper records (including backups) to ensure the information can never be reconstructed or misused (internal or 3rd party).
Discovery
Before any classification can take place, the organization needs to know what data it actually has and where it lives. This means conducting a data discovery and inventory, understanding and mapping how information flows across systems, and identifying where restricted or classified data might be exposed or duplicated. Without this prerequisite, any classification effort will not be complete and might result in decisions based on assumptions. Having an up-to-date data inventory also helps reveal gaps — like shadow or forgotten repositories. In a perfect world, organizations should rely on automated discovery toolsets to keep inventories current and reduce manual work, especially as data constantly moves across applications and environments
Automation v/s Manual Classification
While manual classification can work in smaller environments, or specific use-cases (sending email, saving a document), it does not scale well. Relying on people label data is inconsistent and often subjective. Automated tools can scan data sources, recognize patterns, and apply classification labels consistently. Data owners still need to review results, but automation ensures coverage, scalability and consistent repeatability.
Access Controls
Access control is where data classification becomes actionable. Once data is categorized, the next step is deciding who should have access and under what conditions. The principle of least privilege should be embedded in every decision — users, applications, and systems should only have the minimum access necessary to perform their function.
Each classification level should dictate the strength of controls. For example, restricted data requires strong authentication (including MFA), application of segmentation/zero-trust principles, encryption at rest and in transit, continuous monitoring, and detailed audit logging. Confidential data may still need encryption and access review but with slightly more flexibility. Lower classifications can rely on standard business access controls.
Beyond access, effective governance should ensure segregation of duties such as preventing one individual from having full control over both data and its approval. Monitoring and alerting mechanisms should be in place to detect unusual access patterns or misuse.
When implementing your systems, work around information classification it is supposed to handle. Also, pay attention to systems which do not process Restricted data, but connected to the network that transmits Restricted data – that system might be subject to stricter regulations just because it can be used to enable lateral movement in case of the successful attack. (Such requirements should be outlined in your standards)
Data Attributes and Collections Library
When the organization has outlined its requirements through Governance, the list of data attributes should be reviewed on continuous basis. Also, the library should contain Collections – a collection of data comprised of lower classification attributes that, collectively, create a collection of higher classification (toxic combination).
Awareness and Training
Policies alone don’t work unless staff know what to do and understand classification decisions. Effective governance ensure that employees are trained, understand and follow defined model.
Provide role-based training, reference guides and periodic attestations to staff to enforce application of labels and handling.
All other documents used by the company should use the consistent approach to information description. If you talk about PII, ensure to mention that PII is discussed within the scope of Restricted data.
Labeling and Metadata
Every piece of data should carry a label that reflects its classification, so it can be recognized by systems enforcing DLP and access policies. Labels should accompany the data, such as embedded in document, stored as file metadata, or applied as tags.
Data “flavors”
Data could take many forms. Let’s think about some of it. Data could live in multiple forms. Let’s dissect it.
- Modeled data: Defined, governed, predictable — essential for analytics, compliance, and automation.
- Non-modeled data: Raw, flexible, and often faster to collect but harder to govern or integrate.
- Semi-structured bridges both worlds, supporting agility with partial structure (e.g., JSON).
- Unstructured data often contains the richest insights (e.g., text, voice, images) but requires advanced tools (AI/NLP/CV) to extract meaning.
To expand it:
| Data Type | Description | Modeled Data (Schema/Defined Structure) | Non-Modeled Data (Ad-hoc/Undefined Structure) | Typical Storage / Examples |
|---|---|---|---|---|
| Structured | Highly organized data that fits neatly into tables or fields. It follows a strict schema and is easy to query with SQL or similar tools. | – Relational databases (MySQL, PostgreSQL, Oracle)- Data warehouses- ERP systemsExamples: Customer tables, financial transactions, HR records | – Temporary tables- Ad-hoc Excel sheets- Flat files (CSV exports without schema enforcement)Examples: One-off reports, unsynced spreadsheets | Databases, CSV files, data marts |
| Semi-Structured | Data with a flexible structure — contains tags or metadata but doesn’t follow a rigid schema. It can be queried using specialized languages (e.g., XPath, JSONPath). | – Defined JSON or XML schemas- Config files with known structures- API payloads with consistent formatting | – Log files with inconsistent fields- Event streams with missing attributes- IoT device outputs with variable data points | JSON, XML, NoSQL (MongoDB, DynamoDB), event logs |
| Unstructured | Data that lacks a predefined model or organizational schema. Often textual, visual, or audio — requires processing or AI to analyze. | – Tagged image datasets- Annotated text corpora- AI training datasets with defined labeling rules | – Free-form documents- Images, videos, emails, recordings, scanned PDFs- Chat messages or social media posts | File systems, content repositories, email archives, SharePoint |
| Hybrid / Multi-Model | Data that combines multiple structures — often seen in modern applications where structured, semi-structured, and unstructured coexist. | – Graph databases (Neo4j)- Document stores with schemas and relationships- Knowledge graphs | – Multi-source datasets (mix of CSV + JSON + text)- ML training data combining tables and raw files | Graph stores, data lakes, federated analytics systems |
Challenges when it comes to applying Data Classification
| Data Type | Description | Challenges When Applying Classification |
|---|---|---|
| Structured | Data stored in databases or tables with well-defined schemas and fields. | – Volume and variety: massive datasets across multiple systems make consistent labeling hard – Data drift: new columns or tables introduced without classification updates – Integration issues: legacy systems may lack metadata tagging capabilities – Overlapping ownership: business vs IT confusion over who classifies – Automation complexity: enforcing classification at query or row level (e.g., column-level encryption) can be technically heavy |
| Semi-Structured | Data with flexible structure (JSON, XML, logs, APIs). | – Schema variability: inconsistent field names, missing tags, or evolving structures. – Lack of standard parsing tools: hard to extract metadata reliably for classification engines. – Hidden sensitive data: personal identifiers may appear deep in nested objects. – Versioning drift: changing API payloads break classification rules. – Context dependency: sensitivity often depends on value combinations, not individual fields. |
| Unstructured | Free-form data like text, images, audio, video, PDFs, or chat logs. | – Low visibility: difficult to scan or index (especially in images, scans, or audio) – Context ambiguity: natural language and tone make automated classification error-prone – Volume explosion: storage grows exponentially, overwhelming manual review processes – Sensitive data in non-obvious places: e.g., SSNs inside images or documents – Tooling gaps: requires AI/ML (NLP, OCR, CV) to interpret and classify accurately |
| Hybrid / Multi-Model | Systems that combine structured, semi-structured, and unstructured data (data lakes, graph stores, etc.). | – Complex interdependencies: data may inherit sensitivity from linked or embedded sources – Inconsistent labeling models: structured data might be classified, but attached files aren’t – Scalability: uniform classification across disparate systems (databases, files, streams) is hard to maintain – Policy enforcement: different storage technologies handle access control differently – Auditability: tracing lineage and maintaining consistent classification through transformations is challenging |
Logs might present another challenge — for example, it may leak some Restricted data and need classification even though file appears generic, thus preventing this would require either filtering out/reduction in log data, or deploying expensive security controls around it.
Third Parties
Classification and handling requirements must flow from company’s Governance (policies, standards) into vendor contracts, shared-responsibility documents etc. It also must cover their backups and non-prod/test environments.
Exceptions
When a risk isn’t “officially” accepted, it’s still accepted in practice — the organization continues doing business, just with weaker controls and a distorted view on reality. It doesn’t change the exposure but rather hides it.
An organization must have a clear exception process and there are multiple ways to build it. The simplest way is to build it into the existing issue management program, so when a control cannot be implemented or partially effective, it’s logged as an exception with a defined owner, action plan, and timeline for resolution. This approach keeps exceptions transparent.
Conclusion
I tried to outline some of the most important points that should be addressed by the company when building their data governance and management layers. It is an opinion, point of reference and informative piece, and should not be treated as a final solution.
It is a challenge to classify data. To navigate it, companies deal with a lot of complexities. In some cases, classification and handling of data presents so much challenge, that some ‘assume’ the lower classification of data on assets and hope that the environment and its complexity won’t come us as a result of the audit (it is especially a pain point when it comes to legacy custom-built heavy processing file extract-transform-load platforms). This definitely not a sign of a good security culture, but I’ve seen it happen.
Implementing effective Data Classification and Handling Governance and Management is complex. It requires broad knowledge and competencies among various groups of people. Finally, it is expensive. But, regardless of challenges, business objectives drive the need, and if you faced with such challenges, then do it right – proper approach will benefit the company in the long run.
I hope you’ve enjoyed the read!
Leave a Reply